
Immer mehr Machine-Learning-Modelle laufen produktiv und generieren kontinuierlich neue Vorhersagen. Damit steigt der Bedarf, diese Predictions, Features und Labels in Echtzeit zu erfassen, zu überwachen und zu analysieren.
Genau hier kommt Google Cloud Pub/Sub ins Spiel – ein skalierbarer, verteilter Nachrichtendienst, der Ereignisse zuverlässig und nahezu in Echtzeit zwischen Systemen austauscht. Für Data-Science-Teams ist Pub/Sub ideal, um Vorhersagen, Features, Monitoring-Daten oder Label-Events zu streamen – z. B. für Online-Model-Monitoring, Feature-Backfills oder Near-Real-Time-Dashboards.
In diesen Beitrag wird die Anwendung von Pub/Sub anhand eines Beispiels erklärt:
- Wir simulieren Modellvorhersagen in Python (Publisher) und senden sie als JSON an Pub/Sub.
- Eine Cloud Function mit Pub/Sub-Trigger konsumiert die Nachrichten und schreibt sie in BigQuery.
- So entsteht eine robuste Pipeline für Online-Monitoring von Metriken (z. B. Score-Verteilung, Latenzen)
Warum Pub/Sub in Data-Science-Projekten?
- Entkopplung von Produzenten (Model Serving, ETL) und Konsumenten (Monitoring, Persistenz, Alarmierung).
- Skalierbarkeit & Verlässlichkeit: Hoher Durchsatz, At-least-once-Zustellung, Dead-Letter-Queues.
- Nahezu Echtzeit: Events stehen innerhalb von Millisekunden zur Verfügung.
- Ökosystem: Einfache Integration mit BigQuery, Cloud Functions, Cloud Run, Dataflow (Apache Beam), Vertex AI.
Typische Data Science Use-Cases:
- Streaming von Predictions & Features → Monitoring in BigQuery / Looker.
- Drift- & Qualitätsmetriken als Events → Alerts bei Schwellwertverletzung (Cloud Monitoring).
- Label-Events (Delayed Feedback) → Modell-Performance in Echtzeit aktualisieren.
- Experiment-Telemetrie aus Notebooks / Pipelines → zentrale, versionierte Speicherung
Beispiel eines Events
Prediction-Events könnten beispielsweise so aussehen:
{
"model": "churn_xgb_v12",
"prediction": 0.78,
"label": null,
"request_id": "a3f7...",
"latency_ms": 42,
"features": {"age": 33, "plan": "pro", "tenure_months": 14},
"ts": "2025-10-26T12:34:56.789Z"
}Projekt vorbereiten
Wie immer in GCP erstellen wir zunächst eine Projekt in der GCP Console oder direkt in GCloud(hier „pubsubtest2025). In GCloud loggen wir uns ein, Updaten die Komponenten, aktivieren das Projekt und setzen die Quota.
gcloud auth login
gcloud components update
gcloud projects create pubsubtest2025 --name="PubSubTest2025"
gcloud config set project pubsubtest2025
gcloud auth application-default set-quota-project pubsubtest2025Anschließend müssen wir die notwendigen APIs konfigurieren:
gcloud services enable pubsub.googleapis.com bigquery.googleapis.com cloudfunctions.googleapis.com run.googleapis.com logging.googleapis.com eventarc.googleapis.com cloudbuild.googleapis.comAußerdem müssen wir unserem Service-Account noch die entsprechenden Rechte zuweisen:
Wir benötigen folgenden Service Account, wobei wir die Projektnummer über folgenden Befehl herausfinden können:
gcloud iam service-accounts listservice-$PROJECT_NUMBER@gcf-admin-robot.iam.gserviceaccount.comgcloud projects add-iam-policy-binding 832320697727 --member="serviceAccount:service-832320697727@gcf-admin-robot.iam.gserviceaccount.com" --role="roles/artifactregistry.writer"Big Query Dataset und Tabelle erstellen
Ebenfalls in der Google Cloud Shell erstellen wir anschließend ein Big Query Dataset mit dem Namen „ds_monitoring“. Das DataSet kann man sich anschließend auch in der GCP Console unter BigQuery/Studio anzeigen lassen.
bq --location=EU mk -d --description "Monitoring für Prediction-Events" ds_monitoringüber bk mk –table erzeugen wir dann noch eine Tabelle mit Namen „predictions“. Due Tabelle hat mehrere Spalten, welche den Werten unseres Prediction-Events entsprechen.
bq mk --table ds_monitoring.predictions ts:TIMESTAMP,model:STRING,prediction:FLOAT,label:FLOAT,request_id:STRING,latency_ms:INTEGER,features:JSONPub/Sub Topic & Subscription anlegen
Nun müssen wir in Pub/Sub ein sogenanntes Topic anlegenund dafür eine Subscription erstellen.
gcloud pubsub topics create ds-predictionsWir legen eine Subscription für den Pull an. Diese wird vom Function-Trigger normalerweise auch automatisch verwaltet, kann aber auch explizit so angelegt werden:
gcloud pubsub subscriptions create ds-predictions-sub --topic=ds-predictions --ack-deadline=60Hinweis: Für produktive Systeme empfiehlt sich zusätzlich eine Dead-Letter-Subscription mit
--dead-letter-topic.
Cloud Function als Subscriber erstellen
Nun entwickeln wir eine Cloud Funktion, die Pub/Sub-Nachrichten konsumiert, decodiert und in BigQuery schreibt. Den Code dafür erstellen wir lokal, bspw. in VSCode. Wir benötigen folgende Dateien:
Dateistruktur lokal (z. B. in cf_subscriber/):
cf_subscriber/
├── main.py
├── requirements.txt
└── runtime.txt # optional: python Version pinnen
requirements.txt:
google-cloud-bigquery==3.*
google-cloud-pubsub==2.*
main.py:
import base64
import json
import os
from google.cloud import bigquery
BQ_DATASET = os.getenv("BQ_DATASET", "ds_monitoring")
BQ_TABLE = os.getenv("BQ_TABLE", "predictions")
TABLE_ID = f"{os.getenv('GCP_PROJECT')}.{BQ_DATASET}.{BQ_TABLE}"
bq_client = bigquery.Client()
def pubsub_to_bq(event, context):
# event['data'] ist Base64-codiert
data = base64.b64decode(event.get("data", b"{}")).decode("utf-8")
obj = json.loads(data)
# Minimal-Validierung & Defaults
row = {
"ts": obj.get("ts"),
"model": obj.get("model", "unknown"),
"prediction": float(obj.get("prediction")),
"label": obj.get("label"),
"request_id": obj.get("request_id"),
"latency_ms": int(obj.get("latency_ms", 0)),
"features": json.dumps(obj.get("features", {})) # als JSON-Feld
}
errors = bq_client.insert_rows_json(TABLE_ID, [row])
if errors:
# Fehler bewusst loggen – Pub/Sub wird neu zustellen (At-least-once)
raise RuntimeError(f"BigQuery insert failed: {errors}")
runtime.txt
python312Deploy (2nd gen, Pub/Sub-Trigger):
Wechsle in der Google Cloud CLI in dein lokales Verzeichnis „cf_subscriber“ und führe folgenden Code aus:
gcloud functions deploy ds-predictions-subscriber --gen2 --runtime=python312 --region=europe-west3 --source=. --entry-point=pubsub_to_bq --trigger-topic=ds-predictions --set-env-vars=BQ_DATASET=ds_monitoring,BQ_TABLE=predictions --memory=256Mi --timeout=60s
Wenn das funktioniert hat, dann kann man manuell direkt testen, ob das senden von Nachrichten funktioniert:
gcloud pubsub topics publish ds-predictions --message "{\"ts\":\"2025-10-26T10:00:00Z\",\"model\":\"demo\",\"prediction\":0.92,\"label\":1,\"request_id\":\"abc123\",\"latency_ms\":53,\"features\":{\"x\":1.23,\"y\":4.56}}"
Alternative: Statt Cloud Functions kann Cloud Run mit einem Push-Subscription-Webhook genutzt werden – praktisch für komplexere Services.
Publisher erstellen
Lokaler Code, der Prediction-Events erzeugt und sendet – ideal zum Testen oder als Teil eines Serving-Backends.
Installation (lokal):
pip install google-cloud-pubsub==2.*Publisher-Code (publisher.py oder in Notebook-Zelle):
import json
import time
import uuid
from datetime import datetime, timezone
from google.cloud import pubsub_v1
PROJECT_ID = "pubsubtest2025"
TOPIC_ID = "ds-predictions"
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(PROJECT_ID, TOPIC_ID)
import random
def make_event():
return {
"model": "churn_xgb_v12",
"prediction": round(random.random(), 4),
"label": None, # labels können später kommen
"request_id": str(uuid.uuid4()),
"latency_ms": random.randint(20, 120),
"features": {
"age": random.randint(18, 80),
"plan": random.choice(["free", "pro", "enterprise"]),
"tenure_months": random.randint(0, 60)
},
"ts": datetime.now(timezone.utc).isoformat()
}
for _ in range(100):
event = make_event()
data = json.dumps(event).encode("utf-8")
future = publisher.publish(topic_path, data=data, source="notebook")
_ = future.result() # optional warten
time.sleep(0.05)
print("100 Events published")
Sofern Du mit gcloud korrekt angemeldet bist, kannst Du den Code einfach lokal ausführen und die Ergebnisse werden in den GCP Projekt übertragen,
gcloud auth application-default loginAlternativ könnte der Code auch über eine VertexAI Workbench direkt auf GCP in einem Notebook ausgeführt werden. Auch Deployments in Cloud Run, Cloud Run Job oder Cloud Funktion deployed werden.
Tipp: Setze sinnvolle Message Attributes (oben
source="notebook"), um downstream zu filtern/partitionieren.
Verifizieren & Auswerten
Die Ergebnisse kannst Du direkt in der GCP Console anzeigen lassen. Dort findest Du verschiedene Messwerte und auch entsprechende Logs:
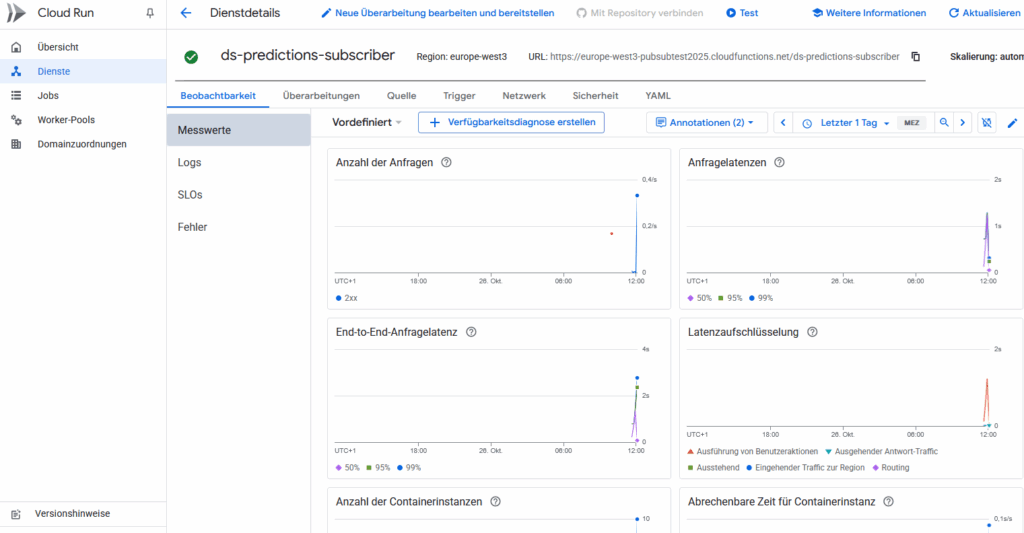
Logs der Function mit Gcloud prüfen:
gcloud functions logs read ds-predictions-subscriber --region=europe-west3 --limit=20BigQuery prüfen (Beispiel-Queries):
-- Letzte 10 Events
SELECT * FROM ds_monitoring.predictions ORDER BY ts DESC LIMIT 10;
-- Score-Verteilung
SELECT
ROUND(prediction, 1) AS bucket,
COUNT(*) AS n
FROM ds_monitoring.predictions
GROUP BY bucket
ORDER BY bucket;
-- Latenz-Statistik nach Modell
SELECT model,
APPROX_QUANTILES(latency_ms, 101)[OFFSET(50)] AS p50,
APPROX_QUANTILES(latency_ms, 101)[OFFSET(95)] AS p95
FROM ds_monitoring.predictions
GROUP BY model;
Dashboarding: Verbinde das Dataset mit Looker Studio oder Looker für Live-Visualisierungen (Score-Verteilung, Latenzen, Throughput).
Best Practices (kurz & praxisnah)
- Schema-Versionierung: Felder unter
featuresversionieren oder mittels JSON-Feld flexibel halten. - Reihenfolge: Pub/Sub garantiert nicht globale Reihenfolge. Bei Bedarf per
ordering_keyarbeiten (z. B. prorequest_idoderuser_id). - Idempotenz: Verbraucher so bauen, dass doppelte Nachrichten keinen Schaden anrichten (z. B. Upserts in BigQuery, Dedupe-Keys).
- Dead-Letter: Für fehlgeschlagene Zustellungen ein Dead-Letter-Topic konfigurieren und Alerts setzen.
- Backpressure: Bei hohem Durchsatz Pull-Subscriber (Cloud Run/Dataflow) mit korrektem Ack/Nack-Handling nutzen.
- Kostenkontrolle: Datenvolumen & Speicherzeit im Auge behalten; BigQuery-Tabellen ggf. partitionieren/cluster.
- Sicherheit: Least-Privilege-IAM für Publisher/Subscriber; sensible Features verschlüsseln oder pseudonymisieren.
Clean-up
Wichtig: Am Ende aufräumen um unnötige Kosten zu vermeiden.
gcloud functions delete ds-predictions-subscriber --region=europe-west3 --gen2 --quiet
gcloud pubsub subscriptions delete ds-predictions-sub --quiet
gcloud pubsub topics delete ds-predictions --quiet
bq rm -f -t ds_monitoring.predictions
bq rm -f -d ds_monitoring
Fazit
Mit wenigen Schritten lässt sich Pub/Sub als Event-Bus für Data-Science etablieren: Predictions werden gestreamt, Monitoring schreibt nach BigQuery, Dashboards werden nahezu in Echtzeit versorgt. Von hier ist der Sprung zu produktiven, skalierbaren Streaming-Workloads (Dataflow, Vertex AI, Looker) klein..


