
Baumbasierte Verfahren wie bspw. XGBoost (Extreme Gradient Boosting) sind die mit am weitesten verbreiteten Machine-Learning-Frameworks. Fast alle Data Scientisten kennen mindestens eines dieser Framework und wenden sie häufig an. In diesem Beitrag soll erklärt werden, wie baumbasierte Verfahren und insbesondere Gradient Boosting funktioniert und wie man es in der Praxis anwenden kann.
Daten
In den folgenden Beispielen verwenden wir den allseits beliebten Iris-Datensatz, der in sklearn einfach geladen werden kann:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# Daten laden
data = load_iris()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Entscheidungsbäume
Um XGBoost zu verstehen, sollte man zunächst verstehen, wie ein einfacher Entscheidungsbaum funktioniert. Ein Entscheidungsbaum ist ein einfaches Modell, das Daten basierend auf Entscheidungsregeln in Untergruppen aufteilt. Es funktioniert nach einem sehr einfachen Wenn-Dann-Prinzip.
Es gibt verschiedene Algorithmen welche unterschiedliche Regeln für die Trennung der Klassen oder die Auswahl der Features für die Trennung implementieren. Einen einfachen Entscheidungsbaum kann man in sklearn so erstellen:
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
# Entscheidungsbaummodell erstellen und trainieren
clf = DecisionTreeClassifier(max_depth=3, random_state=42)
clf.fit(X_train, y_train)
# Genauigkeit ausgeben
print("Genauigkeit des Entscheidungsbaums:", clf.score(X_test, y_test))
# Entscheidungsbaum visualisieren
plt.figure(figsize=(12, 8))
plot_tree(clf, feature_names=data.feature_names, class_names=data.target_names, filled=True)
plt.title("Visualisierung des Entscheidungsbaums")
plt.show()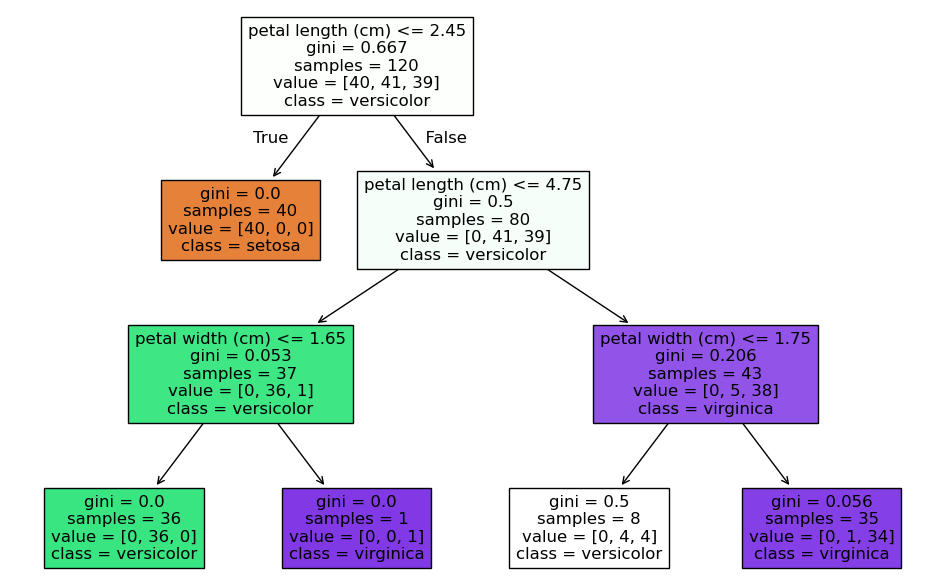
Random Forest
Random Forest ist eine Ensemblemethode. Statt nur einen Entscheidungsbaum zu generieren werden mehrere unterschiedliche Bäume erzeugt, deren Vorhersage kombiniert wird. Dadurch wird vor allem das Overfitting reduziert, das beim Trainieren nur eines Baums entsteht. Die Zufälligkeit der Bäume wird dadurch erreicht, dass jeweils zufällige Stichproben aus den Trainingsdaten generiert werden (=Bootstrapping)
Bootstrapping
Bootstrapping ist eine Möglichkeit um aus einer Stichprobe mehrere unterschiedliche Stichproben zu erzeugen, die der gleichen Verteilung folgen. Dies erreicht man, indem man aus dem Datensatz mehrere Zufallsstichproben MIT zurückliegen zieht.
Weitere Zufallselemente bei der Erzeugung der Bäume sind beispielsweise, dass pro Baum nur ein zufällige Auswahl an Features berücksichtigt wird.
Die Vorhersage bei Random Forest Modellen wird dann durch Mehrheitsentscheid (bei Klassifikationsaufgaben) oder durch den Durchschnittswert (bei Regressionsaufgaben) erreicht.
Beispiel Random Forest
from sklearn.ensemble import RandomForestClassifier
# Random-Forest-Modell erstellen und trainieren
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
# Genauigkeit ausgeben
print("Genauigkeit des Random Forest:", rf.score(X_test, y_test))Random Forest hat deutlich weniger Overfitting als einfache Entscheidungsbäume, jedoch Schwierigkeiten mit stark unbalancierten Daten.
Boosting und Adaboost
Boosting ist eine Technik um in einem Ensemble aus Modellen schwache Lerner (wie Entscheidungsbäume) zu einem starken Ensemble zu kombinieren. Anders als beim Random Forest werden diese Bäume dabei nicht gleichzeitig trainiert, sondern nacheinander (also iterativ) erzeugt. Bei jedem Durchlauf werden fehlerhafte Vorhersagen höher gewichtet. Bei jeder Iteration werden die Gewichte der falsch klassifizierten Punkte erhöht und die Gewichte der korrekt klassifizierten Punkte reduziert.
Die endgültige Vorhersage enteht durch eine gewichtete Mehrheitsentscheidung bzw. einen gewichteten Durchschnitt aller Bäume.
from sklearn.ensemble import AdaBoostClassifier
# Adaboost-Modell erstellen und trainieren
adaboost = AdaBoostClassifier(n_estimators=50, random_state=42)
adaboost.fit(X_train, y_train)
# Genauigkeit ausgeben
print("Genauigkeit von Adaboost:", adaboost.score(X_test, y_test))XGBoost
XGBoost entwickelt die Idee von Adaboost weiter, wobei sukzessive weitere Bäume trainiert werden, die jeweils die Fehler der vorherigen Bäume minimiert.
Bei jedem Durchlauf wird die Abweichung zwischen aktueller Vorhersage und dem tatsächlichen Wert berechnet. Zur Optimierung verwendet XGBoost das Gradientenabstiegsverfahren. Das bedeutet, dass der negative Gradient der Verlustfunktion als Zielgröße für den nächsten Baum verwendet wird. Bei Regression ist das beispielsweise der MSE.
Die einzelnen Bäume werden so erzeugt, dass der Gradient in den entstehenden Blättern minimiert wird. Die Ergebnisse des neuen Baums werden dann mit einem Gewicht (Lernrate) zur Gesamtvorhersage hinzugefügt.
Zusätzlich führt XGBoost zwei Arten von Regularisierung ein:
- L1-Regularisierung (Lasso): Bestraft die Anzahl der genutzten Parameter
- L2-Regularisierung (Ridge): Bestraft die Größe der Parameter
import xgboost as xgb
from sklearn.metrics import accuracy_score
# DMatrix erstellen (spezielles Datenformat für XGBoost)
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
# XGBoost-Modell trainieren
params = {
'objective': 'multi:softmax', # Multiklassenvorhersage
'num_class': 3, # Anzahl der Klassen
'max_depth': 3, # Maximale Tiefe der Bäume
'eta': 0.1, # Lernrate
'lambda': 1, # L2-Regularisierung
'alpha': 0 # L1-Regularisierung
}
bst = xgb.train(params, dtrain, num_boost_round=50)
# Vorhersagen
preds = bst.predict(dtest)
# Genauigkeit ausgeben
print("Genauigkeit von XGBoost:", accuracy_score(y_test, preds))LightGBM
LightGBM wurde ursprünglich von Microsoft entwickelt und hat sehr viele Ähnlichkeiten mit XGBoost. Ein Unterschied ist, dass LightGBM die Bäume nicht nach Tiefe konstruiert, sondern den am stärksten fehlerhaften Blattknoten auswählt und ihn erweitert. Tendenziell sorgt das gleichmäßige erweitern aller Blätter einer bestimmten Tiefe zwar für stabilere Modelle, allerdings ist das erweitern des jeweilst am stärksten fehlerhaften Blattknotens schneller. Dadurch entstehen sehr tiefe, aber effiziente Bäume. Zusätzlich unterstützt LightGBM auch paralleles trainieren per GPU, wodurch es sich besonders für große Datensätze besonders gut eignet.
Ein Nachteil von LightGBM ist, dass es zum Overfitting neigt. Ähnlich wie XGBoost unterstützt es aber verschiedene Varianten der Regulierung (L1, L2, Feature-Subsampling und Bagging).
lgb_model = lgb.LGBMClassifier(n_estimators=100)
lgb_model.fit(X_train, y_train)
y_pred_lgb = lgb_model.predict(X_test)
print(f"LightGBM Accuracy: {accuracy_score(y_test, y_pred_lgb):.4f}")CatBoost
CatBoost ist ähnlich eine weitere Variante von auf Gradiente Boosting basierenden Entscheidungsbäumen. Die Besonderheit von CatBoost ist, dass es besonders auf die Verarbeitung von kategorialen Daten ausgelegt ist. Dabei verwendet es eine spezielle Technik namens „Ordered Target Statistics“, welche kategoriale Werte basieren auf dem Zielwert sinnvoll codiert. Zusätzlich verwendet es Ordered Gradient Estimation, wodurch CatBoost etwas besser generalisiert. CatBoost unterstützt ebenso wie LightGBM auch das Training auf GPUs. Allerdings dauert das Training im allgemeinen etwas länger. Es ist also besonders gut geeignet für Datensätze mit vielen kategorialen Features oder Aufgaben mit hoher Overfitting-Gefahr.
cat_model = cb.CatBoostClassifier(iterations=100, verbose=0)
cat_model.fit(X_train, y_train)
y_pred_cat = cat_model.predict(X_test)
print(f"CatBoost Accuracy: {accuracy_score(y_test, y_pred_cat):.4f}")

