
In diesem Beitrag soll gezeigt werden, wie man ein einfaches Modell auf der Google Cloud mit Vertex AI bereitstellen kann. Wie man grundsätzlich mit GCP arbeitet kann man in diesem Beitrag nachlesen.
Den Code findet ihr hier.
Datensatz auf BigQuery hochladen
Im ersten Schritt wollen wir einen Beispieldatensatz auf BigQuery hochladen.
from google.cloud import bigquery
import pandas as pd
# GCP-Projekt & BigQuery Dataset
PROJECT_ID = "vertex2025"
DATASET_ID = "gochx_data"
TABLE_ID = "gochx_table"
# Erstelle einen BigQuery-Client
client = bigquery.Client(project=PROJECT_ID)
## Dataset erstellen
# Dataset-Referenz
dataset_ref = client.dataset(DATASET_ID)
# Prüfen, ob Dataset existiert, sonst erstellen
try:
client.get_dataset(dataset_ref)
print(f"Dataset {DATASET_ID} existiert bereits.")
except:
dataset = bigquery.Dataset(dataset_ref)
dataset.location = "US"
dataset = client.create_dataset(dataset)
print(f"Dataset {DATASET_ID} wurde erstellt.")
## Tabelle erstellen
# Tabelle definieren
schema = [
bigquery.SchemaField("feature1", "FLOAT"),
bigquery.SchemaField("feature2", "FLOAT"),
bigquery.SchemaField("label", "INTEGER"),
]
table_ref = client.dataset(DATASET_ID).table(TABLE_ID)
# Prüfen, ob Tabelle existiert, sonst erstellen
try:
client.get_table(table_ref)
print(f"Tabelle {TABLE_ID} existiert bereits.")
except:
table = bigquery.Table(table_ref, schema=schema)
table = client.create_table(table)
print(f"Tabelle {TABLE_ID} wurde erstellt.")
# Dummy-Daten als Pandas DataFrame
data = pd.DataFrame({
"feature1": [1.2, 2.4, 3.1, 4.8, 5.0],
"feature2": [3.5, 1.2, 7.8, 3.2, 5.5],
"label": [0, 1, 1, 0, 1]
})
# Lade Daten nach BigQuery hoch
table_ref = f"{PROJECT_ID}.{DATASET_ID}.{TABLE_ID}"
job = client.load_table_from_dataframe(data, table_ref)
job.result() # Warte auf Abschluss
print(f"Daten in BigQuery hochgeladen: {table_ref}")
Modell trainieren
Im zweiten Schritt trainieren wir ein einfaches Modell mit Vertex AI. Wichtig ist, dass wir die gleiche Version von sklearn verwenden, die wir später auch auf GCP verwenden. In diesem Fall 1.5.2.
pip install -U scikit-learn==1.5.2Um das Modell zu trainieren verwenden wir folgenden Code:
# Wichtig: Man brauch Version 1.5: pip install -U scikit-learn==1.5.2
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import joblib
from google.cloud import bigquery
import pandas as pd
# GCP-Projekt & BigQuery Dataset
PROJECT_ID = "vertex2025"
DATASET_ID = "gochx_data"
TABLE_ID = "gochx_table"
# Erstelle einen BigQuery-Client
client = bigquery.Client(project=PROJECT_ID)
def load_data_from_bigquery():
query = f"SELECT * FROM `{PROJECT_ID}.{DATASET_ID}.{TABLE_ID}`"
df = client.query(query).to_dataframe()
return df
df = load_data_from_bigquery()
print("Daten geladen:", df.head())
# Daten vorbereiten
X = df.drop(columns=["label"]).values
y = df["label"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Modell trainieren
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Modell speichern (richtiges Format für Vertex AI)
model_filename = "model.joblib"
joblib.dump(model, model_filename)
print("Modell gespeichert als model.joblib")Optional kann schon lokal getestet erden, ob das Modell korrekt ausgeführt wird.
Modell auf GCP speichern
Als nächstes legen wir auf GCP unter „Cloud Storage“ einen neuen Bucket an. Dorthin wollen wir das Modell hochladen. Dafür verwenden wir folgenden Code:
from google.cloud import aiplatform
from google.cloud import storage
import os
# GCP-Setup
PROJECT_ID = "vertex2025"
BUCKET_NAME = "gochx_bucket"
GCS_MODEL_FOLDER = "models/my_model"
MODEL_FILE_NAME = "model.joblib"
GCS_MODEL_PATH = f"gs://{BUCKET_NAME}/{MODEL_FILE_NAME}"
# Modell lokal speichern
#model_path = "model.pkl"
#joblib.dump(model, model_path)
#print(f"Modell lokal gespeichert als {model_path}")
# Cloud Storage Client initialisieren
storage_client = storage.Client(project=PROJECT_ID)
# Datei in den Bucket hochladen
bucket = storage_client.bucket(BUCKET_NAME)
blob = bucket.blob(f"{GCS_MODEL_FOLDER}/model.joblib")
blob.upload_from_filename("model.joblib")
print(f"Modell erfolgreich nach Cloud Storage hochgeladen: {GCS_MODEL_PATH}")Model Registry
Nun endlich können wir das Model in die Model Registry laden. Dazu verwenden wir folgenden Code:
from google.cloud import aiplatform
# GCP-Setup
PROJECT_ID = "vertex2025"
BUCKET_NAME = "gochx_bucket"
GCS_MODEL_FOLDER = "models/my_model"
# Vertex AI-Setup
aiplatform.init(project=PROJECT_ID, location="us-central1")
# Modell hochladen
model = aiplatform.Model.upload(
display_name="random_forest_model",
artifact_uri=f"gs://{BUCKET_NAME}/{GCS_MODEL_FOLDER}/",
serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-5:latest"
)
print("Modell erfolgreich hochgeladen:", model.resource_name)Hinweis: Hier wurde das ältere Paket „aiplatform“ verwendet. Google zieht momentan alles um auf das neuere Paket vertex AI. Den Code kann man dort genauso verwenden, der Import heiß´t aber nun:
from vertexai.resources import Model
Wichtig ist hier, dass der Serving Container die entsprechenden Pakete enthält. Hier verwende ich einen sklearn CPU Container in der Version 1-5.
Das Modell liegt nun in der Model Registry und kann auch dort ausgeführt werden, bspw. für eine Batch Prediction.
Modell als Rest-API deployen
In unserem Fall wollen wir das Modell aber nicht nur für Batch-Predictions nutzen, sondern als Rest-API bereitstellen. Dafür müssen wir einen Endpoint erzeugen und das Modell mit diesem Endpoint verbinden. Die Model-ID bekommt ihr aus den vorherigen ausgaben bzw. aus der Model Registry in der Google Konsole unter Vertex AI / Model Registry:
from google.cloud import aiplatform
# GCP-Setup
PROJECT_ID = "vertex2025"
LOCATION = "us-central1"
MODEL_ID = "5844419972582866944" # Deine Modell-ID
ENDPOINT_NAME = "random_forest_endpoint"
# Vertex AI initialisieren
aiplatform.init(project=PROJECT_ID, location=LOCATION)
# Modell aus der Vertex AI Model Registry abrufen
model = aiplatform.Model(f"projects/{PROJECT_ID}/locations/{LOCATION}/models/{MODEL_ID}")
# Endpunkt erstellen
endpoint = aiplatform.Endpoint.create(display_name=ENDPOINT_NAME)
print(f"Endpunkt erstellt: {endpoint.resource_name}")
# Modell zum Endpunkt deployen (also mit dem Endpunkt verbinden)
deployed_model = endpoint.deploy(
model=model,
machine_type="n1-standard-4",
traffic_split={"0": 100} # Alle Anfragen an dieses Modell leiten
)
print(f"Modell erfolgreich als API bereitgestellt: {endpoint.resource_name}")
print(f"Dein REST API Endpoint ist: {endpoint.predict}")Das bereitgestellte Modell können wir dann direkt in der Google Cloud Konsole testen:
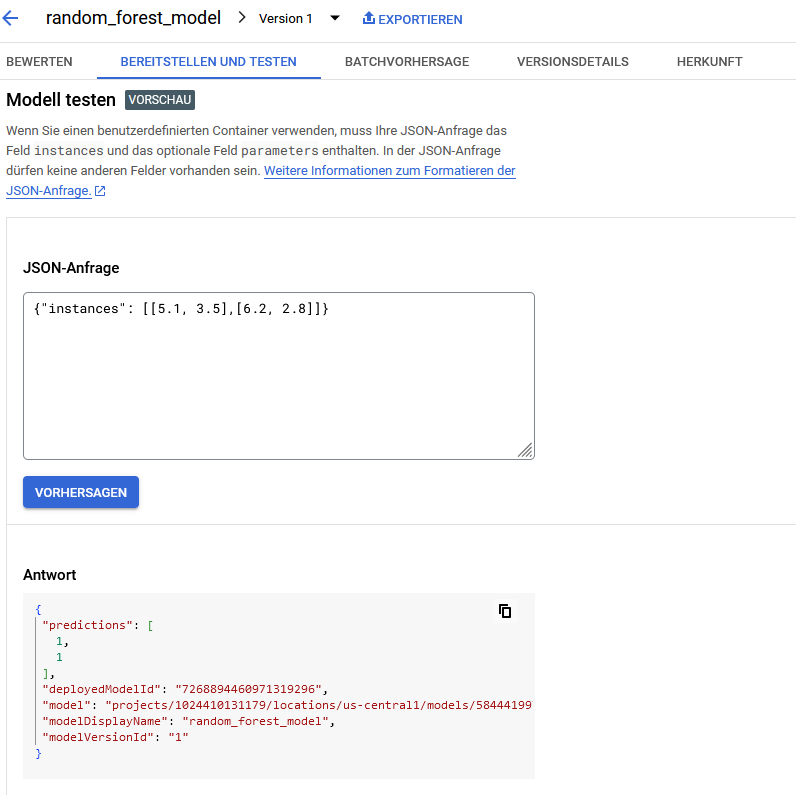
Rest-API abfragen
Alternativ können wir die API aber auch mit Python abfragen. Das funktioniert so:
import requests
import json
from google.oauth2 import service_account
from google.auth.transport.requests import Request
# Das hier vorher in der Google Cloud Shell ausführen
# gcloud auth application-default login
# 🔹 GCP-Projekt & Endpoint-ID (ohne Komma!)
PROJECT_ID = "1024410131179"
ENDPOINT_ID = "621840895716622336"
# 🔹 Endpunkt-URL
ENDPOINT_URL = f"https://us-central1-aiplatform.googleapis.com/v1/projects/{PROJECT_ID}/locations/us-central1/endpoints/{ENDPOINT_ID}:predict"
# 🔹 Testdaten (müssen die gleichen Features wie das Modell haben!)
test_instance = {
"instances": [
[2.5, 3.1]
]
}
# 🔹 OAuth 2.0 Token explizit generieren
from google.auth import default
credentials, _ = default()
credentials.refresh(Request()) # Aktualisiere das Token
# 🔹 Header mit gültigem Access Token
headers = {
"Authorization": f"Bearer {credentials.token}",
"Content-Type": "application/json"
}
# 🔹 API-Request senden
response = requests.post(ENDPOINT_URL, headers=headers, json=test_instance)
print("API Antwort:", response.json())
Fehlersuche
An verschiedenen Stellen können Fehler auftauchen. Um diese zu entdecken, helfen häufig die Logs. An manchen Stellen benötigt man dabei auch einfach etwas Geduld, v.a. beim deployen des Modells auf dem Endpunkt. Das dauert ein paar Minuten.
Darüber hinaus kann man auch das Modell in der Modell Registry testen, bevor man es auf dem Endpunkt deployed. Zu diesem Zweck sollte man eine JSON Datei erstellen die wie folgt aussieht:
[5.1, 3.5]
[6.2, 2.8]ACHTUNG: Das ist ein anderes Format wie für die Rest-API. Dort ist das Format: {„instances“: [[5.1, 3.5],[6.2, 2.8]]}
Bei Batch muss man hingegen jede Instanz separat einlesen lassen. Alternativ könnte auch dieses Format passen: {„instances“: [5.1, 3.5]}{„instances“: [6.2, 2.8]} oder wenn sklearn Namen für die Features erwartet, dann müssen auch diese angegeben werden.
Diese lädt man in das Cloud Storage Bucket. Endweder per Google Cloud Konsole oder per Befehl:
gsutil cp test_instances.jsonl gs://gochx_bucket/test_instances.jsonlDanach kann man das Modell in der Model Registry per Batch Vorhersage testen:
from google.cloud import aiplatform
# GCP-Setup
PROJECT_ID = "vertex2025"
LOCATION = "us-central1"
MODEL_ID = "5844419972582866944" # Deine Modell-ID aus 4 model2vetex.py
GCS_INPUT_URI = "gs://gochx_bucket/test_instances.jsonl"
GCS_OUTPUT_URI = "gs://gochx_bucket/batch_predictions/"
# Vertex AI initialisieren
aiplatform.init(project=PROJECT_ID, location=LOCATION)
# Modell laden
model = aiplatform.Model(model_name=f"projects/{PROJECT_ID}/locations/{LOCATION}/models/{MODEL_ID}")
# Batch Prediction ausführen
batch_prediction_job = model.batch_predict(
job_display_name="random_forest_batch_prediction",
gcs_source=GCS_INPUT_URI,
gcs_destination_prefix=GCS_OUTPUT_URI,
machine_type="n1-standard-4",
)
batch_prediction_job.wait() # Warten, bis das Batch-Job abgeschlossen ist
print(f"Batch Prediction abgeschlossen! Ergebnisse unter: {GCS_OUTPUT_URI}")
Auch hier dauert es eine Weile bis das Ergebnis erzeugt wird. Zu finden ist es dann im Cloud Storage Bucket unter „Batch_Predictions“.
Aufräumen
Am Ende sollte man nicht vergessen aufzuräumen, um Kosten in der Google Cloud zu sparen:
- Lösche den Endpoint
- Lösche das Modell aus der Model Registry
- Lösche den Cloud Storage Bucket


