
/ds/shap
Machine-Learning-Modelle werden immer leistungsfähiger, aber oft auch komplexer und undurchsichtiger. Während ein einfaches lineares Modell noch leicht zu interpretieren ist, sind Random Forests oder neuronale Netze eher eine „Blackbox“. Genau hier setzt Explainable AI (XAI) an. SHAP ist ein häufig verwendetes und mathematisch fundiertes Verfahren um das Problem zu lösen.
Die Grundidee von SHAP
SHAP (benannt nach Lloyd Shapley) misst den Beitrag von Features zur Gesamtvorhersage eines Machine-Learning-Modells. Es basiert auf der kooperativen Spieltheorie und misst dort den fairen Beitrag jedes Spielers zu einem gemeinsamen Ergebnis in einem Kooperationsspiel.
Der Beitrag eines Features wird durch die Veränderung der Modellvorhersage gemessen, wenn das Feature zu einer bestehenden Kombination hinzugefügt wird. Die Shapley-Werte verteilen den „Gewinn“ so, dass der exakte, faire Beitrag jedes Features ermittelt wird.
Die offizielle Dokumentation findet sich hier.
Berechnung
Koalitionen bilden
Um den fairen Anteil zu berechnen, werden „Koalitionen“ gebildet. Das sind alle möglichen Kombinationen der Features: Kombinationen ganz ohne Features (Baseline), mit nur einem Feature, mit zwei Features, und so weiter.
Das Modell wird gedanklich für jede Koalition zweimal evaluiert:
- Einmal ohne das zu untersuchende Feature xi
- Einmal mit dem Feature xi
Marginaler Beitrag
Der marginale Beitrag ist einfach das Ergebnis der Vorhersage mit und ohne das Feature xi, also die Differenz aus diesen beiden Vorhersagen. Der finale Shapley-Wert für das Feature xi ist das gewichtete Mittel seiner marginalen Beiträge aus allen möglichen Koalitionen. Gewichtet wird dabei so, dass alle Koalitionen gleichmäßig berücksichtigt werden.
Beispiel bei drei Features
Angenommen, wir haben drei Features (x1,x2,x3) und wollen den Shapley-Wert für x1 berechnen. Wir fügen x1 zu jeder möglichen Koalition S hinzu, die x1 noch nicht enthält. Es gibt 2n−1 mögliche Koalitionen (hier also 4):
- Koalition S={} → Beitrag:
- Koalition S={x2} → Beitrag:
- Koalition S={x3} → Beitrag:
- Koalition S={x2,x3} → Beitrag:
Die Gewichtung
Nicht jeder marginale Beitrag zählt gleich. Die Gewichtung für eine Koalition S der Größe ∣S∣ bei n Gesamt-Features berechnet sich wie folgt:
Das ist so zu interpretieren:
- S! ist die Anzahl der Permutationen der Features die ohne xi in der Koalition enthalten sind (also wie viel Kombinationen es gibt). In der ersten Koalition S{} also 0. In der zweiten Koalition S={x2} also 1 usw.
- (n-|S|-1)! ist die Anzahl der Features die nicht enthalten sind (bzw. davon jeweils die Permutation, also wie viel Kombinationen es gibt). In der ersten Koalition S{} also 2 (nämlich x2 und x3). In der zweiten Koalition S={x2} also 1 (nämlich x3) usw.
- n! ist die Gesamtzahl der Permutationen aller n Features
Diese Formel stellt sicher, dass jede „Größen-Ebene“ von Koalitionen mit dem gleichen Gesamtgewicht in die Berechnung eingeht. Hier also:
- Koalition: S={} → Gewicht 1/6
- Koalition: S={x2} → Gewicht 1/6
- Koalition: S={x3}} → Gewicht 1/6
- Koalition: S={x2,x3} → Gewicht: 1/3
SHAP in Python
Man installiert SHAP über pip oder conda:
pip install shap
conda install -c conda-forge shapIm Beispiel wird ein RandomForestClassifier auf dem Iris-Datensatz trainiert. Da SHAP bei Multiclass-Problemen (wie Iris mit 3 Klassen) Werte für jede Klasse berechnet, fokussieren wir der Einfachheit halber bei der Visualisierung auf eine spezifische Klasse oder betrachten den generellen Impact.
import shap
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# 1. Datensatz laden
data = load_iris()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.target
# 2. Datensatz in Trainings- und Testdaten aufteilen
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 3. Modell trainieren
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)Da es sich hier um einen RandomForestClassifier handelt benötigt man aus SHAP den TreeExplainer. Er nutzt die Baumstruktur aus, um die Shapley-Werte exakt und extrem performant zu berechnen..
# SHAP-Erklärungen erstellen
explainer = shap.TreeExplainer(model)
# SHAP-Werte für die Testdaten berechnen
shap_values = explainer.shap_values(X_test)
Visualisierung und Interpretation
SHAP bietet verschiedene Visualisierungen, die globale (Modell insgesamt) und lokale Erklärbarkeit (einzelne Vorhersagen) abdecken.
Globale Erklärbarkeit: Der Summary Plot
Der Summary Plot zeigt für alle Klassen die Stärke des Einflusses des jeweiligen Features. Je größer der Balken, desto Stärker ist der mittlere Einfluss des Features.
# Visualisierung
shap.summary_plot(shap_values, X_test)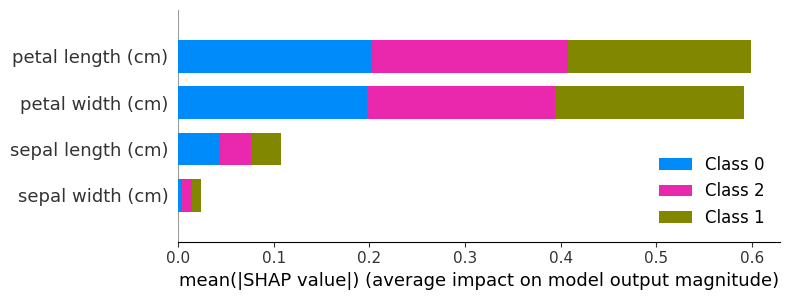
Globale Erklärbarkeit: Der Beeswarm Plot
Der SHAP Beeswarm Plot zeigt nun den Einfluss der Features auf die Modellvorhersage. Jede Zeile entspricht einem Feature, jeder Punkt repräsentiert eine einzelne Vorhersage. Die Farbe zeigt den tatsächlichen Wert des Features an, blau = niedrig, rot = hoch.
Die X-Achse zeigt nun den Einfluss. Je weiter ein Punkt links oder rechts liegt, desto größer ist sein Einfluss. Je weiter rechts ein Punkt liegt, um so mehr erhöht sich die Modellvorhersage, je weiter links er liegt um so mehr senkt sich die Modellvorhersage.
Bei Klassenvorhersagen bedeutet das: Wenn rote Punkte (hohe Feature-Werte) weit rechts liegen, treibt ein hoher Wert in diesem Feature die Modellvorhersage stark nach oben.
# Da Iris 3 Klassen hat, schauen wir uns die Vorhersage für Klasse 1 an
shap.plots.beeswarm(shap_values[:, :, 1])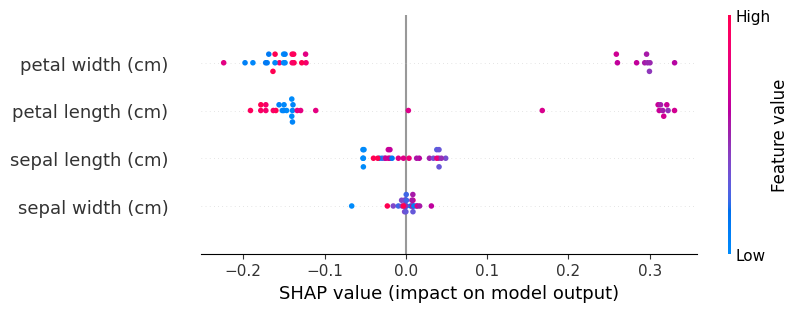
Lokale Erklärbarkeit: Wasserfall Plot
Wenn man wissen möchte, warum das Modell für genau eine bestimmte Blume so entschieden hat hilft der Waterfall Plot. Der Plot startet unten beim Erwartungswert E[f(x)] (dem Basiswert, den das Modell im Durchschnitt vorhersagt). Jedes Feature schiebt diesen Wert nun entweder ins Positive (rot) oder ins Negative (blau), bis ganz oben die finale Vorhersage f(x) für genau diese eine Instanz erreicht wird.
# Waterfall Plot für die allererste Instanz in den Testdaten (für Klasse 1)
shap.plots.waterfall(shap_values[0, :, 1])
Feature-Interaktionen: Der Dependence Plot
Manchmal hängt der Einfluss eines Features vom Wert eines anderen ab. Hier sieht man auf der X-Achse den Wert des Features und auf der Y-Achse seinen SHAP-Wert. Die Einfärbung der Punkte erfolgt automatisch durch das am stärksten interagierende zweite Feature. So lassen sich nicht-lineare Zusammenhänge und Interaktionen zwischen Features aufdecken.
# Dependence Plot für "petal length (cm)" bzgl. Klasse 1
shap.plots.scatter(shap_values[:, "petal length (cm)", 1], color=shap_values[:, :, 1])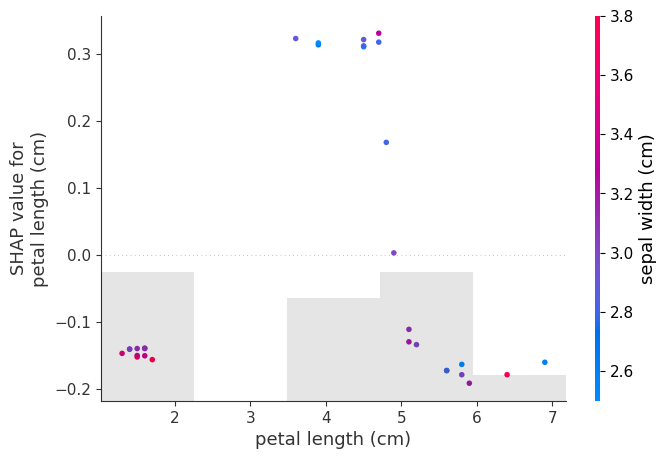
Weitere Verfahren
SHAP ist mittlerweile das Standardverfahren im Bereich Explainable AI. Es gibt aber auch noch weitere Verfahren:
- LIME (Local Interpretable Model-agnostic Explanations): Eine Alternative zu SHAP. LIME versucht nicht, die perfekten Shapley-Werte zu berechnen. Stattdessen trainiert es für jede Vorhersage ein simples, lokales „Surrogate-Modell“ (z.B. eine einfache lineare Regression) direkt um den Datenpunkt herum. LIME ist oft schneller als SHAP, aber mathematisch weniger konsistent.
- Model-Specific vs. Model-Agnostic: Methoden wie Feature Importance in Random Forests oder Attention-Weights in neuronalen Netzen sind modellspezifisch. Sie funktionieren nur für diesen einen Algorithmus. SHAP ist modellagnostisch (mit Varianten wie dem
KernelExplainer, der jedes beliebige Modell erklären kann, auch wenn er rechenintensiver ist). - Globale Feature Importance vs. SHAP: Standard Feature Importance (z.B. Gini-Importance im Random Forest) misst nur, wie oft ein Feature für Splits genutzt wird. Sie zeigt nicht die Richtung des Effekts an (erhöht oder senkt es die Vorhersage?) und kann bei korrelierten Features irreführend sein.


